
Our transition to a new software architecture is a vital move in navigating the dynamic technological landscape. In a recent webinar, we discussed the aspects... Continue reading
Return to previous page
All posts by jasuter
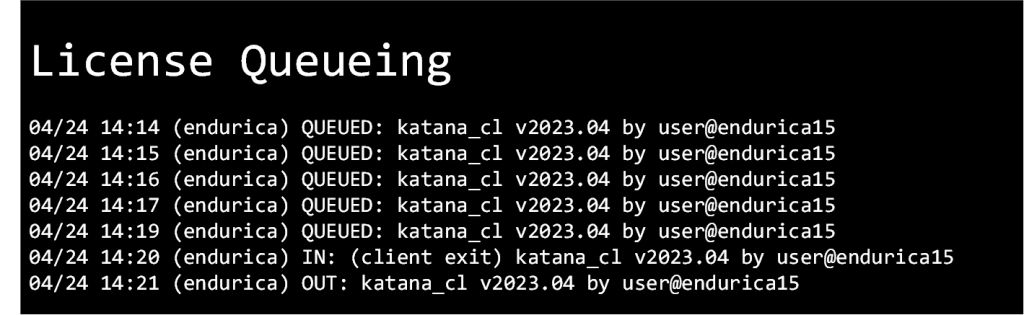
Design optimization studies are driving a need to support the efficient management and execution of many jobs. This is why we are announcing that Endurica’s... Continue reading
Endurica CL Endurica CL received many improvements over the past year. These improvements cover a wide variety of different aspects of the software: Reducing Run-time... Continue reading
Ever wonder what it takes to consistently deliver quality and reliability in our software releases? Here’s a brief overview of the systems and disciplines we... Continue reading
Overview The accuracy of the interpolated results performed by EIE is dependent on the discretization of the map. Specifically, the results will become more accurate... Continue reading
Endurica CL and fe-safe/Rubber provide several material models for defining cyclic crack growth under nonrelaxing conditions. Nonrelaxing cycles occur when the ratio R is greater... Continue reading