

Discover how industry leaders are transforming their durability programs by simulating real-world road loads for rubber parts. This webinar features a verification and validation project... Continue reading
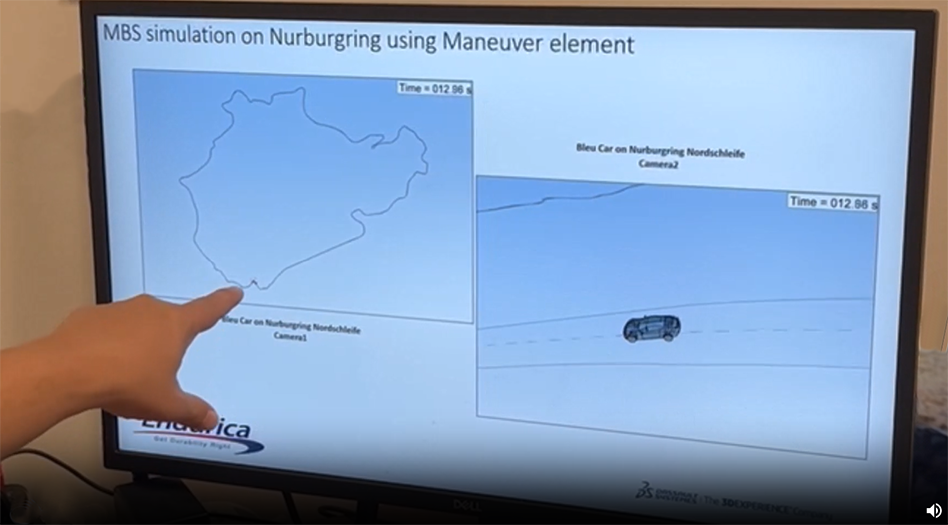
It was May of 2023, and Will Mars had just given a presentation on “Virtual Qualification of the Durability Performance of an Elastomeric Mount with... Continue reading

Wow – this year has really been one of many firsts for Endurica. We had our first ever Community Conference in April, we started our... Continue reading
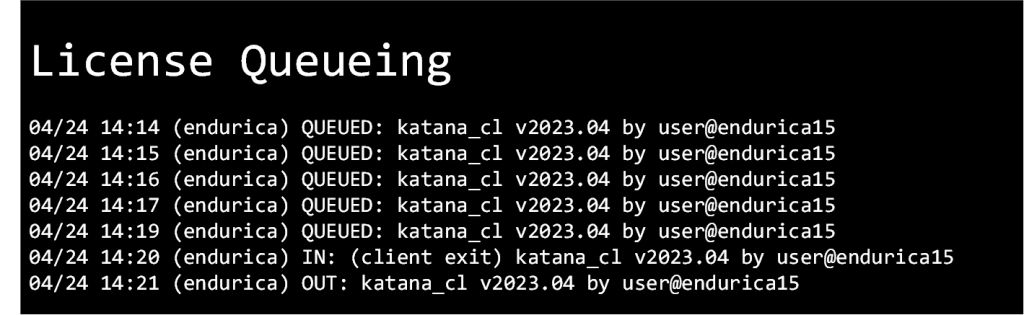
Design optimization studies are driving a need to support the efficient management and execution of many jobs. This is why we are announcing that Endurica’s... Continue reading

2020 is burned in all our minds as a chaotic and tough year. Just like the rest of the world, Endurica staff experienced times of... Continue reading
Endurica CL Endurica CL received many improvements over the past year. These improvements cover a wide variety of different aspects of the software: Reducing Run-time... Continue reading
Overview The accuracy of the interpolated results performed by EIE is dependent on the discretization of the map. Specifically, the results will become more accurate... Continue reading